Someone leaked a massive private source code repository from Yandex. What can you as a data scientist learn from this leak? How is advanced machine learning done at these massive companies. Specifically what does the infrastructure for search look like?
I have not downloaded the source code so I’m basing my ideas on what has been said by arstechnica and several twitter threads.
Search
Search on the internet is essentially a monopsony (there are a few companies doing search and everyone else is bought up or destroyed; the buyer controls the market). In the English speaking world (and most of Europe) there is Google, in Chinese there is Baidu and in Russian you have Yandex. Regardless search is a specific problem with a few well-known parts.
First what do we know about search?
Search, or information retrieval is a set of problems related to presenting the ‘right’ information based on a query. The founders of google wrote a seminal paper about this problem, where they presented the PageRank algorithm to determine which webpages are most important.
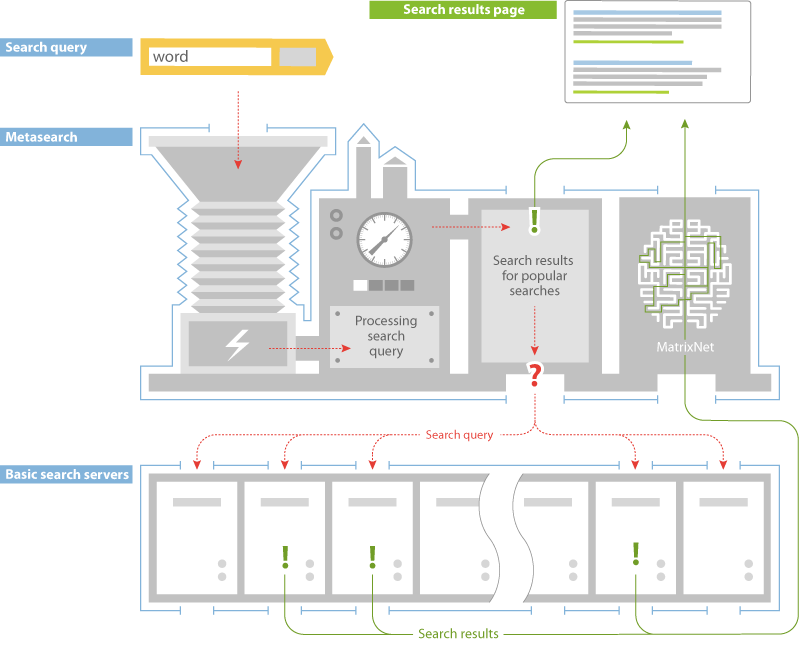
In general search engines work like this: given a search query you retrieve a huge amount of results and use Machine learning to rerank the results (’learning to rank’ if you look for it in academic papers) to present the best results on top^[1].
Especially in websites you have a lot of data, every click is recorded and so you can use that click information to rank the links and train a model to rerank the results.
According to some docs this is what Yandex does (or did in the past):
- enrich query
- retrieve all possibly relevant documents
- get all information (features) about those documents
- sort results based on features and a model
What can we see in the yandex leaks?
Like every machine learning problem you need several things: features (input data), an ML model, serving infrastructure. etc.
- what kind of features are deemed important for search results
- what kind of models does yandex use?
- feeding data into the model
Features that go into search
Approximately 17.000 features go into the ranking algorithm of Yandex. There are link-specific features, site-specific features, and also features related to the searcher and query.
What is inspirational too, is that the features are all documented with a name, description, link to internal wiki, links to people responsible for those features and tags to categorize that feature, to include or exclude the feature for certain languages.
The SEO worshippers on the internet (see links below) have summarized those 17.000 features into the underlying concepts.
According to the excellent Arstechnica article, Yandex ranks results higher that:
- Aren’t too old (age of document vs today, age of url, age of links that refer to that page) interactive feature explorer: age
- Have a lot of organic traffic (unique visitors) and less search-driven traffic
- Have fewer numbers and slashes in their URL
- Have optimized code rather than “hard pessimization,” with a “PR=0”
- Are hosted on reliable servers
- Happen to be Wikipedia pages or are linked from Wikipedia
- Are hosted or linked from higher-level pages on a domain
- Have keywords in their URL (up to three)
very specific things
number of slashes is bad
numbers in url are bad
host reliability (more 400/ 500 errors is bad)
user behavior like: click through rate, last-click, time on site, bounce rate, if users return to site
if your url is the last clicked in a search session (user finds what he/she needs) - This increases your ranking
Conclusion
So search queries are enriched, all relevant documents are retrieved. The results are sorted and the highest scoring ones are shown first.
Like many other ML problems the key to great results is thinking about what information you want the ML model to learn and turning that information into features.
Notes
Generic technical news article by arstechnica: arstechnica: Massive Yandex code leak reveals Russian search engine’s ranking factors
A group of people digged through the source code to see what they could learn for Search engine optimization (SEO).:
- @benwills twitter thread: “After 9 days with the Yandex code, here’s what I’ve found that’s relevant for SEOs.”
- @alex_buraks “The most interesting part for SEO community is: the list of all 1922 ranking factors used in the search algorithm "
- @alex_buraks “Leaked Yandex ranking factors analysis part 2, let’s go.”
- A github repo with lessons learned, seems … empty?
- Rob Ousbey’s compiled search tool.
More info about other yandex things in the leaks:
References
[1]: Whatever that objective is. Right now I feel the objective for google is showing the right ads, for yandex showing the right website results. For bing, I don’t know what their objective is.